
So, one of the more surprising revelations to me when I started into this was that you can't avoid multi-sampling, even if you aren't making a sample-based instrument, and even if you only have one sound. The idea that you can just speed up or slow down a digital sample to change its pitch is only half-true. The same sample played at higher than original speeds is actually not the same wave shape as the original sample. You not only need to drop half the samples to go up an octave, but you need to cut out frequency content that it can no longer accurately represent. Because this instrument doesn't have a discrete set of notes, and is inherently fretless, it also needs perfect continuity when bending from the lowest to the highest note. So the function that defines a wave cycle not only takes phase into account, but the maximum frequency at which you might play it back determines its shape.
And also, because I have a life outside of iOS instrument making, I am always looking to tie-ins to things that I need to know more generally to survive in the job market. I am currently very interested in the various forms of parallel computing; specifically vector computing. Ultimately, I am interested in OpenCL, SIMD, and GPU computing. This matches up well, because with wavetable synthesis, it is possible in theory to render every sample in the sample buffer in parallel for every voice (multiple voices per finger when chorusing is taken into account).
So with Cantor, I used Apple's Accelerate.Framework to make this part of the code parallel. The results here have been great so far. I have been watching to see if OpenCL will become public on iOS (no luck yet), but am preparing for that day. The main question will be whether I will be able to use the GPU to render sound buffers at a reasonable rate (ie: 10ms?). That would be like generating audio buffers at 100 fps. The main thing to keep in mind is the control rate. The control rate is the rate at which we see a change in an audio parameter like a voice turning on, and how long until that change is audible. If a GPU were locked to the screen refresh rate and that rate was 60fps, then audio latency will be too high. 200fps would be good, but we are only going to output 256 samples at that rate. The main thing is that we target a control rate, and ensure that the audio is fully rendered to cover the time in between control changes. It might even be advantageous to render ahead (ie: 1024 samples) and invalidate samples in the case that a parameter changed, which would allow audio to be processed in larger batches most of the time without suffering latency.
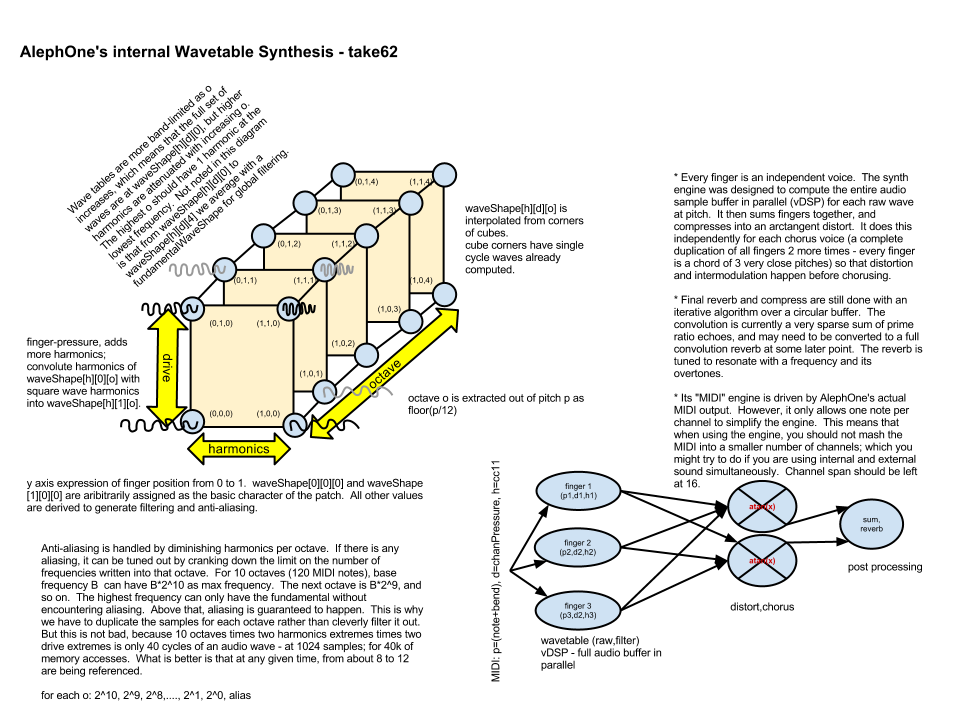
One thing I am not doing explicitly so far is handling interpolation between samples in these samplebuffers. I compensate by simply having large buffers for the single-cycle wave (1024 samples). The single cycle wave in the buffer is circular, so linear interpolation or cubic spline between them are plausible. There is also the issue of the fact that as you go up an octave, the wave is oversampled by 2x because you will skip half the samples. Because of this, a single sample represented in all the octaves could fit in a space that's about 2x the original sample size (n + n/2 + n/4 + n/8 +...).
And finally, there is the issue of control splines themselves. It is currently an ad-hoc ramp being applied to change the volume, pitch, timbre for a voice. It's probably better to think of it as a spline per voice. The spline could be simple linear or cubic (possibly), or the spline could limit changes to prevent impulsing (ie: more explicit volume ramping).
Post Processing:
The part that generates the voices is easily done in parallel, which is why I am thinking about GPU computation. In an ideal world, I load up all of the samples into the card, and when fingers move (at roughly the control rate), the kernel is re-invoked with new parameters, and these kernels always complete by returning enough audio data to cover the time until the next possible control change (ie: 256 samples); or possibly returning more data than that (ie: to cover 2 or 3 chunks into the future that might get invalidated by future control changes) if it doesn't increase the latency of running the kernel.
I am not sure if final steps like distortion and convolution reverb can be worked into this scheme, but it seems plausible. If that can be done, then the entire audio engine can essentially be run in the GPU, and one of the good side effects of this would be that patches could be written as a bundle of shader code and audio samples, which would allow for third-party contributions or an app to generate the patches - because these won't need to be compiled into the app when it ships. This is very much how Geo Synthesizer and SampleWiz work together right now, except all we can do is replace samples. But the main question is one of whether I can get a satisfactory framerate when using the GPU. I have been told that I won't beat what I am doing any time soon, but I will investigate it just because I have an interest in what is going on with CUDA, OpenCL anyhow.
OSC, MIDI, Control:
And of course, it would be a waste to make such an engine and only embed it into the synth. It might be best to put an OSC interface on it to allow controller, synth, patch editor to evolve separately. But if OSC was used to eliminate the complexity of using MIDI (the protocol is the problem ...the pipe is nice), then the question of whether to use a mach port or a TCP port becomes a question. And also an issue of what kind of setup hassles and latency issues have now become unavoidable.